海量数据处理
概述
海量数据处理, 就是基于海量数据的查找, 统计, 运算等操作.
海量数据是指数据量太大, 所以导致要么无法在较短时间内迅速解决, 要么无法一次性装入内存. 从而导致传统的操作无法实现.
分治 -- Hash 映射
所有散列函数都有如下一个基本特性: 如果两个散列值是不相同的(根据同一函数), 那么这两个散列值的原始输入也是不相同的.
对大文件进行处理时, 若文件过大, 无法一次性读入内存, 可以考虑采取 Hash 映射的方法, 将文件中的元素映射到不同小文件中, 然后再依次处理各个小文件, 最后合并处理结果.
如, 给定 a, b 两个文件, 各存放 50 亿个 url, 每个 url 各占 64B, 内存限制是 4GB, 如何找出两个文件共同的 url?
方案:
遍历文件 a, 对每个 url 求 hash(url)%1024, 然后根据所取得的值将 url 分别存储到 1024 个小文件中. 这样每个小文件大约为 300MB.
遍历文件 b, 采取和 a 相同的方式将 url 分别存储到 1024 个小文件中. 这样处理后, 所有可能相同的 url 都在对应的小文件中.
堆排序
如果需求是寻找最大的前 K 个数, 或最小的 K 个数, 则可以使用堆排序.
先读入 K 个数, 构建大顶堆/小顶堆, 然后遍历后续的数字, 与堆顶数字进行比较, 并进行调整, 遍历完成后, 堆剩下的数字就是所求的数字. 时间复杂度为 O(nlogk), 空间复杂度为 O(1).
Bit-map
Bit-map 的原理是使用 bit 数组来表示某些元素是否存在, 由于采用了 bit 为单位来存储数据, 因此在存储空间方面, 可以大大节省, 适用于海量数据的快速查找, 判重, 删除等.
位图排序的例子:
假设要使用位图排序对值区间为 0-7 的 5 个元素(4, 7, 2, 5, 3)排序. 方法如下:
- 要排的数区间在 0-7, 所以需要 8bit, 此时是这样的: 0000 0000
- 遍历元素, 第一个为 4, 则把第 4 个位置置 1, 此时是这样的: 0001 0000
- 第二个是 7, 则把第八个位置置 1, 此时是这样的: 1001 0000
- 如此反复, 直到 5 个元素都处理完, 此时是这样的: 1011 1100
- 将 1 的序号输出(2, 3, 4, 5, 7)即可.
再如:
已知某个文件内部包含一些电话号码, 每个号码为 8 位数字, 统计不同号码的个数.
方案: 8 位数字表示的最大数为 99999999, 可以理解为从 0-99999999 的数字, 用 bit-map 解决, 可以让一个数字对应一个 bit, 所以 99999999 用 12MB 就足够表示了. 然后依次读入每个电话号码, 将 bitmap 相应位置为 1, 最后统计 bitmap 中 1 的位数, 即为不同号码的个数.
布隆过滤器
布隆过滤器是一个包含了 m 位的位数组, 数组的每一位都初始化为 0, 然后定义 k 个不同的 Hash 函数, 每个 Hash 函数都可以将集合中的元素映射到位数组中的某一位.
当向集合中插入一个元素时, 根据 k 个 Hash 函数可以得到位数组中的 k 个位, 将这些位全部设为 1. 如果一个位置多次被置为 1, 则只有第一次会起作用, 后面几次都没有任何效果.
要查询某个元素是否属于集合时, 就使用 k 个哈希函数得到此元素对应的 k 个位, 如果所有点都是 1, 那么元素在集合内, 如果有 0, 则元素不在集合内.
如, 刚开始时, 将 m 位的位数组的每一位都初始化为 0:

假设有集合 S={x1, x2, ..., xn}, 使用 k 个相互独立的 Hash 函数, 将元素映射到 {1, ..., m} 的范围中(每个元素都会被哈希 k 次). 如图:
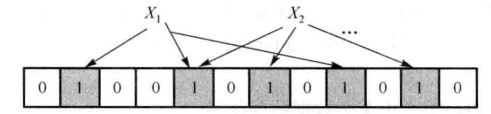
如果要判断 y 是否属于这个集合, 则就 y 使用 k 次哈希函数, 如果 h(y) 对应的位置都是 1, 则认为 y 在集合中, 否则不在集合中.
布隆过滤器中的位数 m 通常比集合中的最大元素小得多, 所以它是一种空间效率和时间效率都很高的随机数据结构, 但这种高效有一定代价, 即存在一定的误判.
倒排索引
倒排索引也常被称为反向索引, 置入档案或反向档案, 这是一种索引方法, 被用来存储在全文检索下某个单词在一个文档或者一组文档中的存储位置的映射. 它是文档索引系统中最常用的数据结构.
适用于搜索引擎的关键字查询.
如:
有如下需要被索引的文本:
T0="it is what it is" T1="what is it" T2="it is a banana"
得到倒排索引文件:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
当用户检索的条件为 "what", "is" 和 "it" 时, 分别查询这三个关键词对应的文本集合, 然后求对应的集合的交集, 得到 {0, 1}, 于是返回 T0, T1.
倒排索引在处理复杂的多关键字查询时, 可在倒排表中先完成查询的并, 交等逻辑运算, 得到结果后再对记录进行存取.
Generated by Emacs 25.x(Org mode 8.x)
Copyright © 2014 - Pinvon - Powered by EGO
